
在当今数据驱动的时代,数据分析已经成为各行各业不可或缺的一部分,无论是商业决策、科学研究还是政策制定,都需要依赖大量的数据和科学的分析方法,对于普通人来说,面对复杂的数据和繁琐的分析过程,往往感到困惑和无从下手,本文将通过一个具体的案例——7777788888管家婆资料,科学解答解释落实_3D50.38.50,来详细解析数据分析的过程和方法,帮助读者更好地理解和应用数据分析技术。
1. 数据收集与预处理
在进行任何数据分析之前,首先需要收集并预处理数据,数据的质量直接影响到分析结果的准确性和可靠性。
1.1 数据收集
在本案例中,我们使用的数据是“7777788888管家婆资料”,这些数据可能来源于不同的渠道,如数据库、文件、网络爬虫等,为了确保数据的完整性和准确性,我们需要对数据的来源进行验证,并尽可能多地收集相关数据。
1.2 数据清洗
数据清洗是数据预处理的重要步骤之一,原始数据通常包含许多噪音和异常值,需要通过数据清洗来去除这些干扰因素,具体操作包括:
缺失值处理:对于缺失的数据,可以选择删除、填充或插补。
重复数据处理:检测并删除重复的记录,确保每条数据都是唯一的。
异常值检测:使用统计方法(如箱线图、Z-score等)检测并处理异常值。
1.3 数据转换
数据转换是将原始数据转换为适合分析的形式,将文本数据转换为数值数据,或将时间序列数据转换为日期格式,在本案例中,我们需要将“7777788888管家婆资料”中的相关字段转换为数值类型,以便后续的统计分析。
2. 探索性数据分析(EDA)
探索性数据分析(Exploratory Data Analysis, EDA)是数据分析的第一步,旨在通过可视化和统计分析来初步了解数据的分布、关系和潜在模式。
2.1 数据统计描述
我们可以计算一些基本的统计量,如均值、中位数、标准差、最小值和最大值等,这些统计量可以帮助我们快速了解数据的集中趋势和离散程度。
import pandas as pd
假设df是已经清洗和转换好的数据框
mean_value = df['column_name'].mean()
median_value = df['column_name'].median()
std_deviation = df['column_name'].std()
min_value = df['column_name'].min()
max_value = df['column_name'].max()
print(f"Mean: {mean_value}, Median: {median_value}, Std Dev: {std_deviation}, Min: {min_value}, Max: {max_value}")2.2 数据可视化
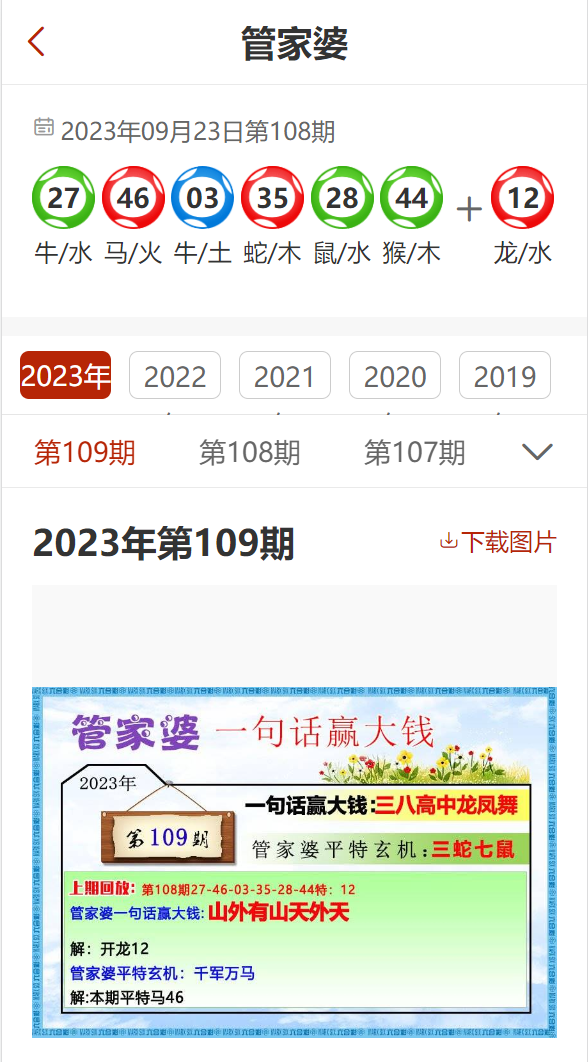
数据可视化是EDA的重要组成部分,通过图表可以直观地展示数据的分布和关系,常用的可视化工具有Matplotlib、Seaborn和Plotly等,以下是一些常见的可视化图表:
直方图:用于展示单个变量的分布情况。
箱线图:用于检测数据的离散程度和异常值。
散点图:用于展示两个变量之间的关系。
热力图:用于展示多个变量之间的相关性。
绘制某个变量的直方图:
import matplotlib.pyplot as plt
plt.hist(df['column_name'], bins=30, edgecolor='black')
plt.title('Histogram of Column Name')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()2.3 相关性分析
相关性分析用于研究两个或多个变量之间的关系强度,常用的相关性系数有皮尔逊相关系数、斯皮尔曼相关系数和肯德尔相关系数,计算两个变量之间的皮尔逊相关系数:
correlation = df[['column1', 'column2']].corr() print(correlation)
3. 建模与预测
在完成EDA之后,我们可以选择合适的模型进行进一步的分析和预测,根据问题的不同,可以选择回归模型、分类模型、聚类模型等。
3.1 特征选择
特征选择是从所有可用的特征中选择最相关的特征,以提高模型的性能和减少过拟合的风险,常用的特征选择方法有过滤法、包裹法和嵌入法,使用随机森林进行特征重要性评估:
from sklearn.ensemble import RandomForestClassifier
X = df.drop('target', axis=1)
y = df['target']
model = RandomForestClassifier()
model.fit(X, y)
importances = model.feature_importances_
feature_names = X.columns
feature_importances = pd.Series(importances, index=feature_names).sort_values(ascending=False)
print(feature_importances)3.2 模型训练与验证
选择合适的模型后,需要进行模型训练和验证,常用的模型有线性回归、逻辑回归、支持向量机、神经网络等,以下是一个简单的逻辑回归模型的训练和验证过程:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
训练模型
model = LogisticRegression()
model.fit(X_train, y_train)
预测
y_pred = model.predict(X_test)
评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(classification_report(y_test, y_pred))3.3 超参数调优
为了进一步提高模型的性能,可以进行超参数调优,常用的超参数调优方法有网格搜索(Grid Search)和随机搜索(Random Search),以下是一个使用网格搜索进行超参数调优的示例:
from sklearn.model_selection import GridSearchCV
param_grid = {
'C': [0.1, 1, 10],
'solver': ['newton-cg', 'lbfgs', 'liblinear']
}
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print(f"Best parameters: {grid_search.best_params_}")
print(f"Best cross-validation score: {grid_search.best_score_}")4. 结果解释与落实
最后一步是对分析结果进行解释,并提出可行的建议和措施,这一步骤至关重要,因为只有将分析结果转化为实际行动,才能真正发挥数据分析的价值。

4.1 结果解释
通过对数据的分析,我们发现了一些关键因素对目标变量的影响,通过特征重要性分析,我们确定了哪些特征对预测结果最为重要;通过相关性分析,我们发现了某些变量之间的强相关性;通过模型训练与验证,我们评估了模型的性能并进行了超参数调优,这些结果为我们提供了宝贵的洞见,帮助我们理解数据背后的规律和趋势。
4.2 落实措施
根据分析结果,我们可以制定一系列具体的措施和建议。
优化资源配置:根据特征重要性分析的结果,优先投入资源到最重要的特征上,以提高整体效率。
改进业务流程:通过相关性分析,找出业务流程中的瓶颈和薄弱环节,进行针对性的改进。
风险管理:利用模型预测结果,提前识别潜在的风险和问题,采取预防措施。
持续监控与反馈:建立持续的数据监控机制,定期更新数据并进行重新分析,以确保措施的有效性和及时调整。
4.3 报告撰写与分享
将整个分析过程和结果整理成一份详细的报告,并与相关人员分享,报告应包括以下几个部分:
背景介绍:简要介绍项目的背景和目的。
数据来源与预处理:说明数据的来源、收集方法和预处理步骤。
探索性数据分析:展示数据统计描述、可视化图表和相关性分析的结果。
模型建立与评估:详细介绍模型的选择、训练过程、评估指标和超参数调优的结果。
结果解释与建议:对分析结果进行详细解释,并提出具体的建议和措施。
结论与展望:总结整个项目的收获和不足,展望未来的研究方向和应用前景



 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号